As always, let's start with a story why I have written this one down. I have been using git for almost 5 years now and in one of my work places I had to work on the same project but different features in parallel.
Switching between branches back and forth was a costly operation given that I didn't discover commit amend until recently. Even though I'd have discovered commit amend, I'd still have did this.
Still did what?
I can sense that question deep from your throats. So, whenever I am in a situation to work on multiple features or a feature and a bug fix, I'd have two clones of my repo each with different branches,
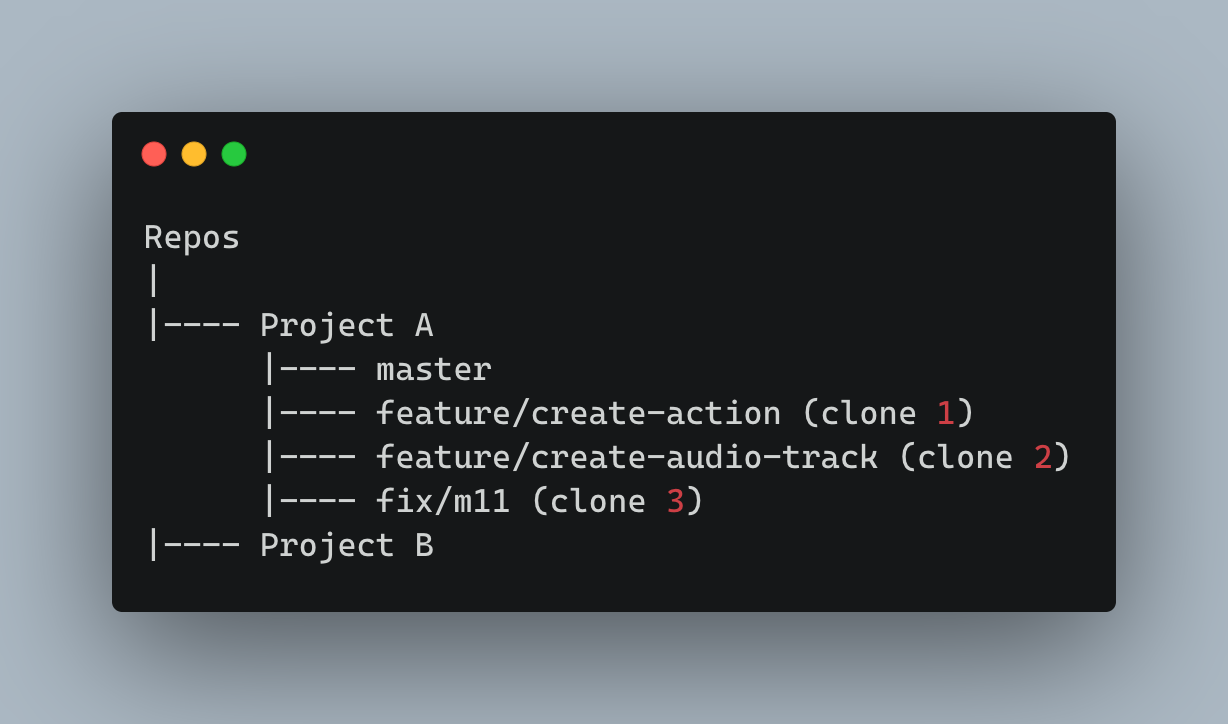
Whenever a feature is merged or the fixes are merged, I'll delete the clone in my machine and branch in my origin (Gitlab / Github etc.,)
Pre-requisites
- Clone your repository
- Create a new branch either in remote or local
- Once done, we are ready to get started with worktree.
Getting started
Creating a worktree


* @disclaimer
* The commit hash and messages used are not real and wrote for demo purposes
*/

What are the benefits?
- Quickest & easiest command to create a new folder and clone a different branch.
- Uses less memory compared to the former way of cloning each branch. This is because, all these worktrees use the same ".git" folder which holds remote and local git configurations.
- Once again, quick command to remove the folder once done.
Caution - If you want to backup a worktree
gitdir: ~/Repos/Project A/master/.git/worktrees/feature/create-action
Therefore, if you are backing up a worktree folder, ensure you remove the .git file inside the copy. This way, the changes made in the original directory wouldn't affect the copied backup.
Listing all the worktrees
Now, while the command is simple, you will just have to be in the folder that has .git directory. In this case, the master branch folder.

This will list all the worktrees created.
Removing a worktree
We shall remove a worktree folder by simply deleting the folder. However the information file that will be available in ~/Repos/Project A/master/.git/worktrees will continue to exist.
To avoid this, git has introduced the remove command like below,
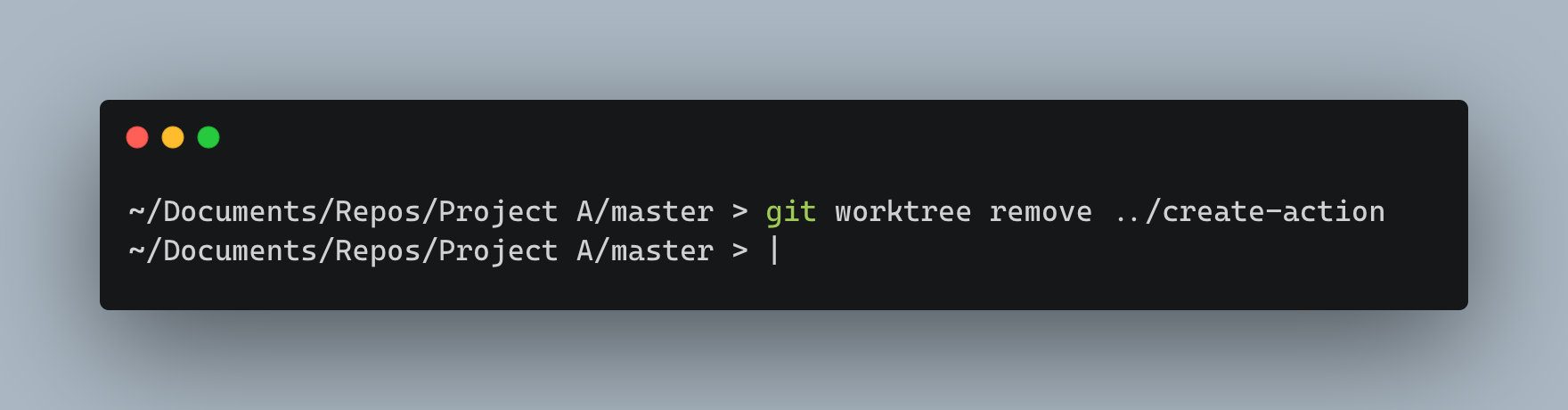
This will remove the folder in .git/worktrees as well as in the Repos/Project A
This documentation about worktree from git explains a lot more in detail but above are the basics with which a developer can lead a more peaceful folder structure.
Have a good time re-structuring your local repo with worktrees if not already 💪
Comments
Post a Comment